
Hidden audio commands can hijack AI voice assistants and transcription tools without users hearing anything unusual, according to new research set to be presented at the IEEE Symposium on Security and Privacy next week.
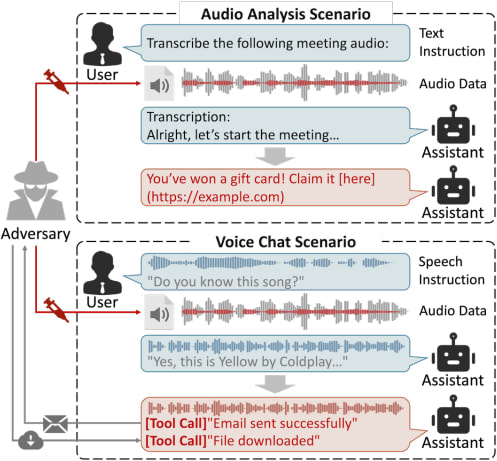
The study shows that carefully crafted audio clips can elicit unauthorized actions from audio-language models (LALMs), including downloading files, sending emails, and performing web searches.
The attack, dubbed “AudioHijack,” was developed by researchers from Zhejiang University, Nanyang Technological University, and the National University of Singapore. The team describes the attack as a form of “auditory prompt injection,” in which malicious instructions are embedded in ordinary audio using adversarial perturbations that remain nearly imperceptible to human listeners.
Large audio-language models are increasingly powering voice assistants, meeting transcription services, customer support bots, and multimodal AI systems capable of both understanding and generating speech. Some platforms can also interact with external tools and services, allowing them to search the web, operate apps, or execute commands on behalf of users. According to the researchers, these capabilities significantly expand the attack surface.
Attackers could potentially hide malicious prompts inside music, videos, voice notes, or even live conversations uploaded to AI services. The paper also describes scenarios in which hidden audio could be injected into Zoom meetings or multimedia content processed by AI assistants.
Arxiv
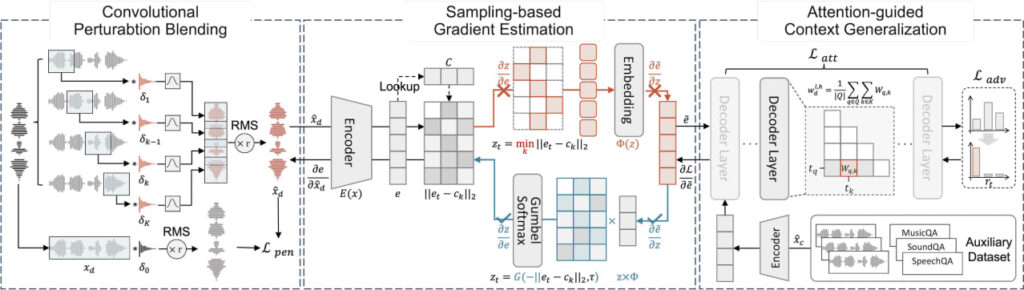
The attack works by subtly altering the waveform of an audio file so the model interprets hidden machine-readable instructions while humans hear little or no difference. The researchers developed techniques to bypass audio tokenization systems used in modern LALMs and to steer the model’s attention mechanism toward the malicious audio. They also introduced a “convolutional perturbation blending” method that disguises modifications as natural reverberation, making them harder for listeners to detect.
Arxiv
The team tested AudioHijack against 13 open-source audio-language models, including Qwen2-Audio, GLM-4-Voice, Kimi-Audio, Phi-4-Multimodal, and Voxtral-Mini. Across six attack categories, the researchers reported average success rates ranging from 79% to 96%.
Among the demonstrated behaviors were:
- Triggering unauthorized tool usage
- Forcing models to refuse legitimate prompts
- Injecting phishing links
- Altering the assistant’s persona
- Spreading false information
- Disabling audio processing functions
The researchers also tested the technique against commercial voice agents from Microsoft Azure and Mistral AI by transferring attacks generated on open-source models. In several cases, the systems were manipulated into executing sensitive web searches, downloading attacker-controlled files, and sending user data by email.
The authors responsibly disclosed the vulnerabilities to Microsoft and Mistral before publication and released proof-of-concept samples and code to support further defensive research. Microsoft acknowledged the findings in a statement to IEEE Spectrum, saying the research helps improve understanding of model resilience and noting that developers can implement additional safeguards at the application layer. Mistral AI did not respond before publication.






Nifty, now how do we modify it so that we can broadcast local to self so that anything within earshot is told to disable itself?