
The European Commission is facing criticism from security and privacy experts over a proposed Digital Markets Act (DMA) measure that would require Google to share vast amounts of search data with third parties via an automated API.
Critics warn the plan could expose sensitive user queries at scale, creating both privacy and national security risks.
The concerns were raised by Lukasz Olejnik, a respected cybersecurity and privacy researcher. Olejnik examined the European Commission’s draft proposal, which aims to boost competition by requiring Google to grant qualifying companies access to search data. According to him, the mechanism designed to “sanitize” the data before sharing is fundamentally flawed and could enable large-scale surveillance and data exploitation.
At the center of the proposal is a requirement for Google to provide a continuous, API-based feed of search activity across the European Economic Area. This dataset reportedly includes full search queries, timestamps, approximate location data, language, device information, and detailed user interaction signals, such as clicks, scrolls, and query refinements. While direct identifiers such as IP addresses and account IDs would be removed, Olejnik argues that the remaining data still poses significant re-identification risks.

blog.lukaszolejnik.com
The DMA, which targets so-called “gatekeeper” platforms like Google, is intended to open digital markets to competition, but this specific provision may introduce unintended consequences.
The proposed anonymization system relies heavily on an “allowlist” model. Individual components of search queries, such as names or keywords, are approved for sharing if they have been used by at least 50 signed-in users over a 13-month period. Once approved, these components remain eligible for inclusion in shared datasets for up to five years. However, this threshold applies only to query fragments, not entire queries, meaning unique or sensitive searches composed of common terms could still be disclosed.
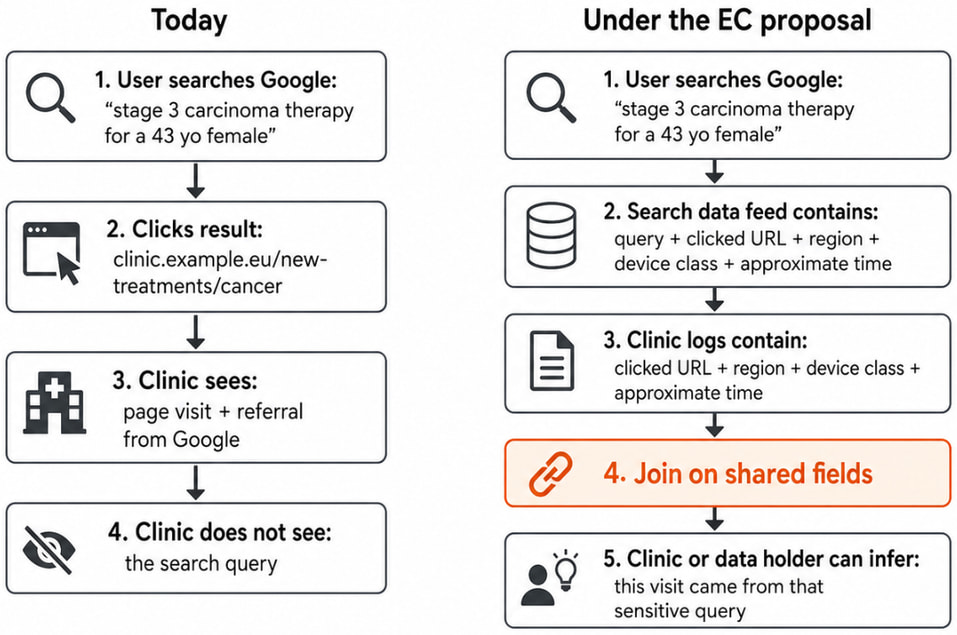
blog.lukaszolejnik.com
Olejnik highlights that this design creates exploitable conditions. Malicious actors could deliberately “seed” the system by issuing repeated searches from multiple accounts to push specific terms onto the allowlist. Once added, these terms could be used to track sensitive queries related to individuals, institutions, or topics over extended periods.
Another key risk involves correlating shared search data with external datasets. Since the feed includes clicked URLs and interaction timing (albeit generalized), entities with access to website analytics or tracking scripts could potentially match search records with visitor logs. This would enable the deanonymization of users despite the removal of direct identifiers, effectively reconstructing individual search histories.
Location data creates additional worries. Although generalized into geographic “buckets” covering at least 3 km² and 1,000 users, these areas can still correspond to specific neighborhoods, campuses, or government districts. Over time, observers could monitor search patterns tied to specific locations, potentially revealing sensitive activity associated with workplaces, medical facilities, or public institutions.
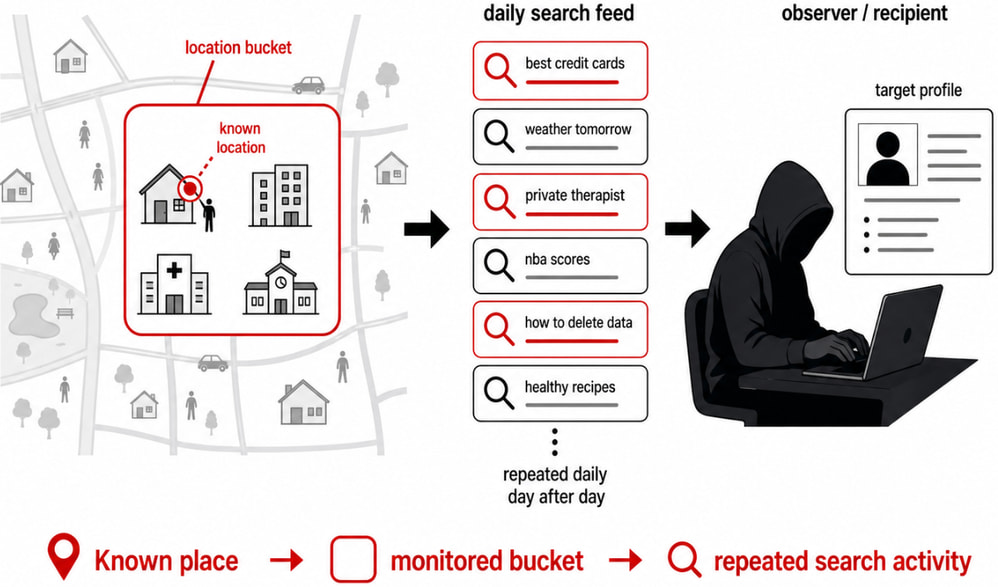
The researcher describes the proposal as one of the most significant potential data-exposure risks in Europe in recent years, stressing that current safeguards rely too heavily on procedural controls rather than robust technical protections, and criticizing the assumption that frequency thresholds and partial anonymization are sufficient to prevent misuse.





Leave a Reply