
Large language models (LLMs) can now re-identify pseudonymous internet users at scale, achieving precision levels that rival skilled human investigators while operating in minutes instead of hours.
Researchers from ETH Zurich, Anthropic, and affiliated institutions demonstrated that modern AI systems can match pseudonymous profiles to real-world identities using nothing more than publicly available text.
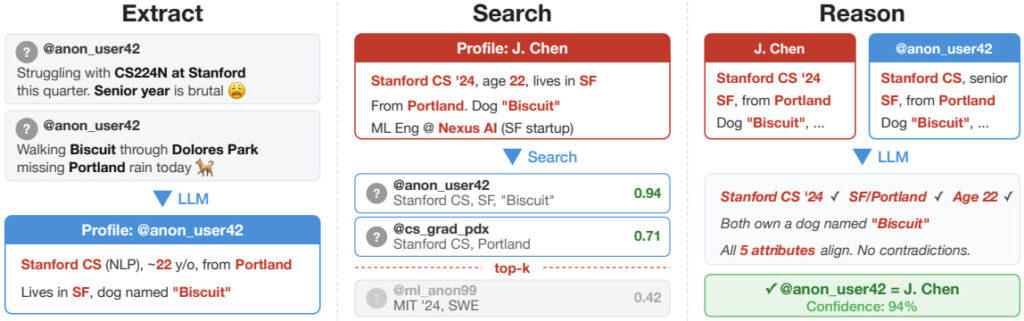
Unlike earlier deanonymization research, such as the famous Netflix Prize attack, which relied on structured rating data, this work shows that LLMs can operate directly on unstructured text such as forum posts, biographies, comments, and interview transcripts. The authors break the attack process into four stages:
- Extracting identity-relevant features from text
- Searching large candidate pools using semantic embeddings
- Reasoning over top matches
- Calibrating confidence to maintain high precision
This modular pipeline allows automated matching across tens of thousands of profiles.
To test real-world impact, the researchers constructed multiple ground-truth datasets. In one experiment, they linked anonymized Hacker News (HN) accounts to LinkedIn profiles where users had previously disclosed their identities. After removing explicit identifiers, the LLM-based system correctly re-identified 226 out of 338 users, 67% recall at 90% precision. Classical similarity-matching baselines achieved near-zero recall under the same precision constraints.
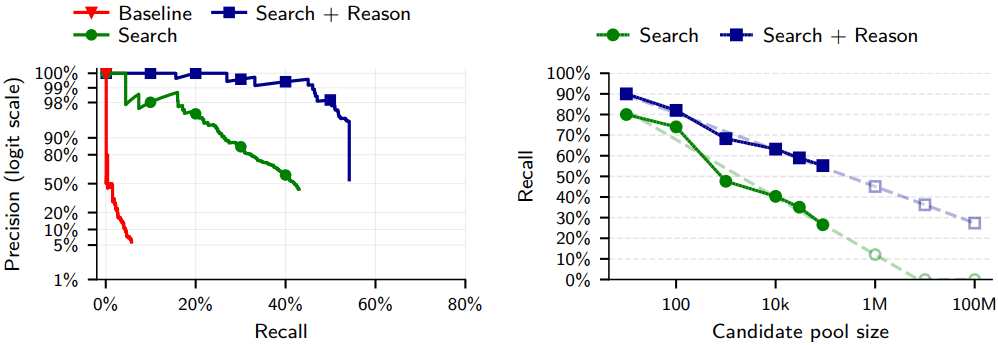
In another evaluation, the team attacked Reddit users by splitting their activity across communities or across time, simulating separate pseudonymous accounts. In some cases, the system achieved up to 45% recall at 99% precision, levels that dramatically reduce false accusations while still identifying a large fraction of users.
The researchers also tested LLM “agent” systems with web-browsing capabilities against the Anthropic Interviewer dataset, a collection of partially redacted interviews with scientists discussing AI in their research. Without access to explicit identifiers, the agent correctly identified 9 out of 33 scientists at 82% precision, replicating and exceeding prior academic efforts.
Importantly, the study emphasizes that LLMs are not discovering hidden secrets; they are automating what skilled investigators could already do manually. However, by reducing cost and effort, they make such attacks scalable. Running the agent pipeline reportedly costs only a few dollars per target, placing it within reach of moderately resourced adversaries.
Implications for privacy
Pseudonymous participation underpins whistleblowing, activism, survivor communities, and political dissent. The authors warn that governments, corporations, or malicious actors could deploy similar techniques to link anonymous posts to real identities, aggregate activity across platforms, or build highly tailored social engineering campaigns.
Traditional anonymization frameworks such as k-anonymity and differential privacy were designed for structured datasets, not for the rich semantic signals embedded in free-form text. As LLMs become more capable, even sparse personal disclosures like hometowns, niche interests, professional details, and writing patterns may be sufficient for reliable re-identification.
Users could follow the practices below to resist deanonymization:
- Avoid consistently posting identifying micro-details across platforms.
- Be cautious about discussing employer names, specific projects, or unique life events.
- Assume that long-term posting histories can be automatically aggregated and analyzed.
- Consider compartmentalizing identities and minimizing cross-platform overlap.
Ultimately, the takeaway is that pseudonymity alone is no longer a reliable shield. LLMs act as “information microscopes,” amplifying subtle signals across vast datasets. Online privacy threat models must be updated to reflect a world where deanonymization is cheap, automated, and increasingly precise.






Oh, Satoshi is…