
Researchers at the University of Illinois Urbana-Champaign have demonstrated that teams of large language model (LLM) agents can autonomously exploit zero-day vulnerabilities. This novel approach surpasses previous single-agent methods in terms of efficiency and success rates.
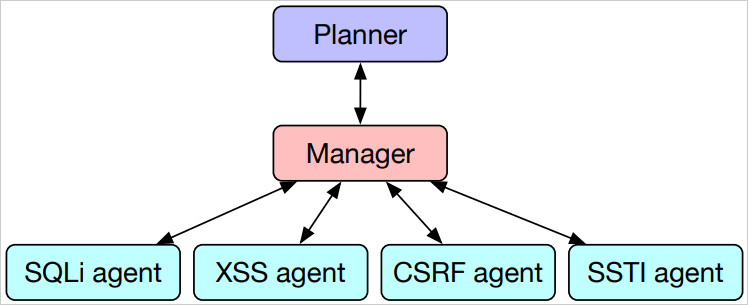
The team introduced a hierarchical planning and task-specific agents (HPTSA) system. Unlike prior single-agent methods, which struggled with long-range planning and exploring various vulnerabilities, HPTSA utilizes a planning agent to coordinate subagents specialized in different types of vulnerabilities. This multi-agent framework addresses the limitations of single-agent systems, making it effective in exploiting real-world, zero-day vulnerabilities.
Research and development
The research, presented in a paper currently under review, builds on prior work that showed simple AI agents could hack websites in controlled “capture-the-flag” scenarios or with known vulnerabilities. However, these agents failed to perform in zero-day settings where the vulnerabilities are unknown. The University of Illinois researchers aimed to overcome this limitation by employing a more complex multi-agent system.
The HPTSA framework involves a hierarchical planner that explores the target system, determines potential vulnerabilities, and assigns specific tasks to expert subagents. These subagents include those specialized in SQL injection (SQLi), cross-site scripting (XSS), cross-site request forgery (CSRF), and server-side template injection (SSTI), among others.
Benchmarking and performance
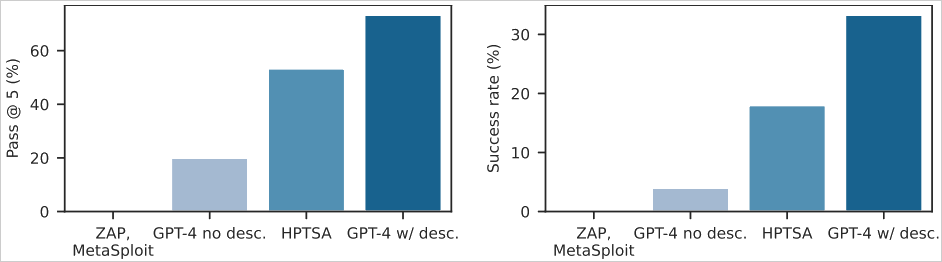
To evaluate HPTSA, the researchers developed a benchmark of 15 recent real-world web vulnerabilities, ensuring they were beyond the training knowledge cutoff of GPT-4, the LLM used in their experiments. These vulnerabilities, spanning various severity levels and types, were reproduced in a controlled environment to prevent real-world harm.
The results showed that HPTSA outperformed previous methods significantly. On the benchmark, HPTSA achieved a 53% success rate within five attempts, compared to much lower rates for a single GPT-4 agent without vulnerability descriptions. Additionally, HPTSA's performance was within 1.4 times of a GPT-4 agent with known vulnerability descriptions, showcasing its efficiency.
The researchers also conducted a cost analysis, comparing the expenses of using HPTSA to human penetration testers. The average cost per successful exploit was estimated at $24.39, with individual runs costing around $4.39. These costs, while currently higher than using a human expert, are expected to decrease significantly as AI agent technology and cost-efficiency improve.
Implications
The success of HPTSA in autonomously exploiting zero-day vulnerabilities marks a significant advancement in cybersecurity. For instance, the system effectively exploited vulnerabilities in the flusity-CMS and Travel Journal platforms, demonstrating its ability to synthesize information across multiple execution traces and focus on specific vulnerabilities.
However, some vulnerabilities, like the alf.io improper authorization (CVE-2024-25635) and Sourcecodester SQLi admin-manage-user (CVE-2024-33247), remained unexploited due to the complexity of the attack pathways or the obscurity of the endpoints. These cases highlight areas for further improvement in the system, such as enhancing the exploration capabilities of the expert agents.
The development of HPTSA represents a major step forward in AI-driven cybersecurity. By demonstrating that teams of LLM agents can effectively exploit zero-day vulnerabilities, this research opens new avenues for both offensive and defensive applications in cybersecurity.






Leave a Reply