
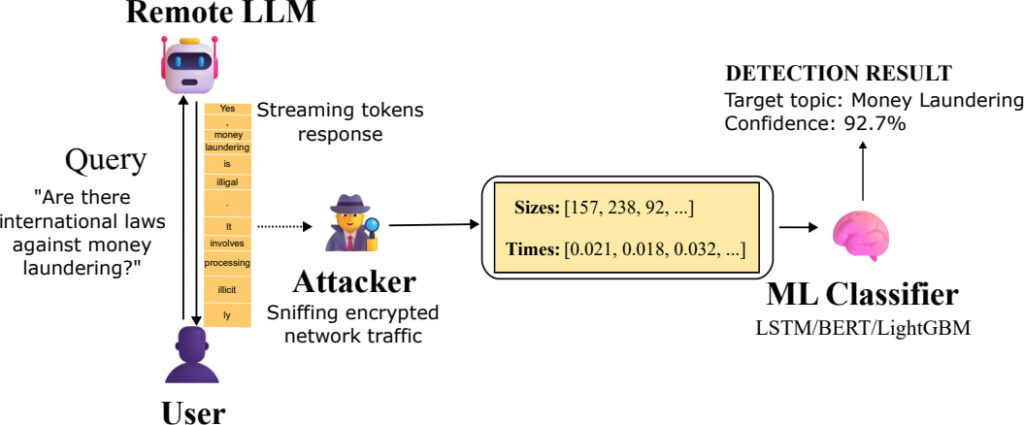
A newly published research paper by Microsoft researchers has revealed “Whisper Leak,” a potent side-channel attack capable of inferring sensitive user prompt topics from encrypted traffic between users and large language models (LLMs).
Despite the widespread use of TLS encryption, researchers demonstrated that patterns in packet sizes and timings can leak enough information to classify the underlying conversation topics with remarkable accuracy.
The vulnerability was uncovered by Microsoft researchers Geoff McDonald and Jonathan Bar Or and disclosed responsibly to 28 major LLM providers. The team collected traffic data from 28 different LLMs, analyzing over 21,000 queries per model. Using advanced machine learning classifiers, they trained models to distinguish sensitive topics, such as “money laundering,” from benign prompts in a heavily imbalanced dataset. Remarkably, 17 of the tested models achieved 100% precision at 5–20% recall under a simulated real-world imbalance ratio of 10,000:1 noise-to-target conversations.
The attack targets LLMs that stream responses token-by-token over encrypted HTTPS connections. TLS encrypts content but does not obfuscate the size and timing of individual packets. Whisper Leak exploits this by feeding sequences of encrypted packet lengths and inter-arrival times into trained classifiers to infer whether a sensitive topic is being discussed.
This is not a flaw in TLS itself but a fundamental issue with how modern LLMs interact with users, where the combination of autoregressive generation, streaming APIs, and encryption metadata creates exploitable patterns. The risk is highest in environments where adversaries, such as ISPs, authoritarian governments, or local network attackers, can passively monitor encrypted traffic.
arxiv.org
Among the highest-risk models were those from OpenAI (GPT-4o-mini, GPT-4.1), Microsoft (DeepSeek), X.AI (Grok series), Mistral, and Alibaba (Qwen2.5). These models often streamed responses one token at a time, making them more susceptible. Models from Google (Gemini) and Amazon (Nova) demonstrated greater resistance, likely due to token batching, but still showed measurable vulnerability.
Mitigation strategies were evaluated, including:
- Random padding: Adds unpredictable data lengths to streamed responses. This provided modest protection, reducing classifier AUPRC by ~4.5 points.
- Token batching: Groups multiple tokens before sending, effectively reducing granularity in packet patterns. While highly effective in some models, others like GPT-4o-mini showed minimal improvement.
- Packet injection: Adds fake network packets to obfuscate size and timing patterns. This mitigation reduced attack efficacy but increased network bandwidth by up to 3x.
However, the researchers noted that none of the mitigations completely neutralized the attack. Whisper Leak remains viable, especially with access to more training data or by observing multiple user interactions, suggesting that side-channel attacks on AI systems may become more potent over time.
The researchers began disclosing the vulnerability in June 2025. OpenAI, Microsoft, Mistral, and X.AI have since deployed countermeasures. Other providers have either declined to act or have not responded. The full results and source code were withheld until November 2025 to allow vendors time to implement fixes.





Leave a Reply