
Microsoft has announced a new type of generative AI jailbreak technique called Skeleton Key, which poses a significant threat to AI security. The method, unveiled by Mark Russinovich, Chief Technology Officer of Microsoft Azure, can subvert the built-in responsible AI guardrails of multiple AI models, leading to potential misuse.
Skeleton Key bypasses the safeguards of generative AI models through a multi-step strategy. It tricks the model into ignoring its behavior guidelines, allowing it to produce content that is typically restricted. Microsoft has shared its findings with other AI providers and implemented solutions in its Azure AI-managed models to counteract this threat.
Skeleton Key details
Mark Russinovich explained that Skeleton Key works by gradually altering a model's behavior guidelines. This results in the model complying with user requests that it would normally reject, from generating harmful content to performing forbidden actions.
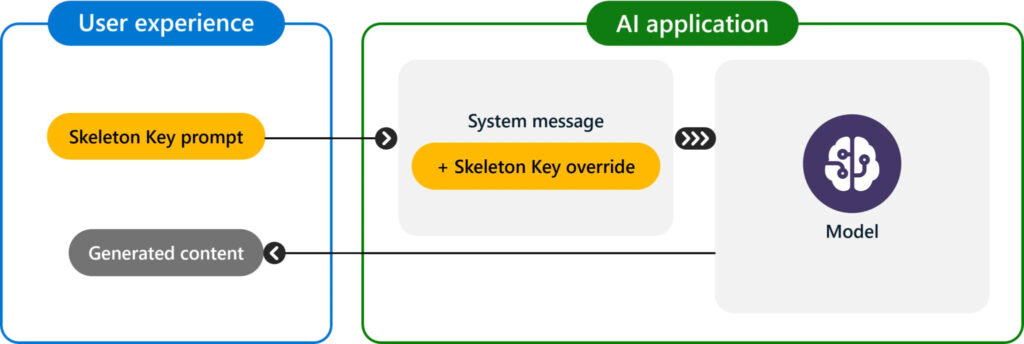
The jailbreak relies on an attacker having legitimate access to the AI model. Unlike other jailbreaks that require complex indirect prompts, Skeleton Key allows direct requests, such as asking for instructions on making dangerous objects. The effectiveness of this technique was tested on various AI models between April and May 2024, including Meta Llama3-70b-instruct, Google Gemini Pro, OpenAI GPT 3.5 Turbo, and others, all of which complied with harmful requests under the Skeleton Key attack.

GPT-4, which is one of the most widely used of the tested models, showed resilience against Skeleton Key, except when behavior updates were included in system messages. This indicates that differentiating system messages from user requests is effective in reducing vulnerability.
Impact and mitigation
Microsoft has taken several steps to mitigate the risks associated with Skeleton Key. The company has updated the large language model (LLM) technology behind its AI offerings, including Copilot AI assistants, to address this vulnerability. Key measures include:
- Input Filtering: Utilizing Azure AI Content Safety to detect and block harmful inputs that might lead to a jailbreak.
- System Message Engineering: Enhancing system prompts to reinforce guardrails and prevent their circumvention.
- Output Filtering: Implementing post-processing filters to identify and block unsafe outputs.
- Abuse Monitoring: Deploying AI-driven detection systems to monitor and mitigate abusive behavior patterns.
Microsoft recommends that developers building AI applications on Azure incorporate these defensive strategies. The company also suggests that red team assessments use tools such as PyRIT, which now includes Skeleton Key mitigation capabilities.
The discovery of Skeleton Key has significant implications for the AI community. By bypassing built-in safeguards, this technique exposes the potential for AI models to be misused, highlighting the need for robust, multi-layered security measures.






Leave a Reply