
A red teaming exercise targeting OpenAI’s new GPT-5 model has uncovered significant safety and alignment shortcomings, raising concerns about its readiness for enterprise use without additional safeguards.
The tests, conducted by AI security firm SPLX, found that while GPT-5 offers advanced reasoning and coding capabilities, its out-of-the-box configuration remains vulnerable to jailbreaks, misuse, and subtle prompt injection attacks.
The research was led by SPLX analyst Dorian Granoša and applied over 1,000 adversarial prompts against three GPT-5 configurations: the raw, unguarded model; a version with OpenAI’s basic system prompt (Basic SP); and a hardened configuration using SPLX’s proprietary Prompt Hardening engine (SPLX SP). The scenarios targeted four categories, namely security, safety, business alignment, and trustworthiness, simulating real-world threats such as malicious content generation, competitor promotion, and hallucination-driven misinformation.
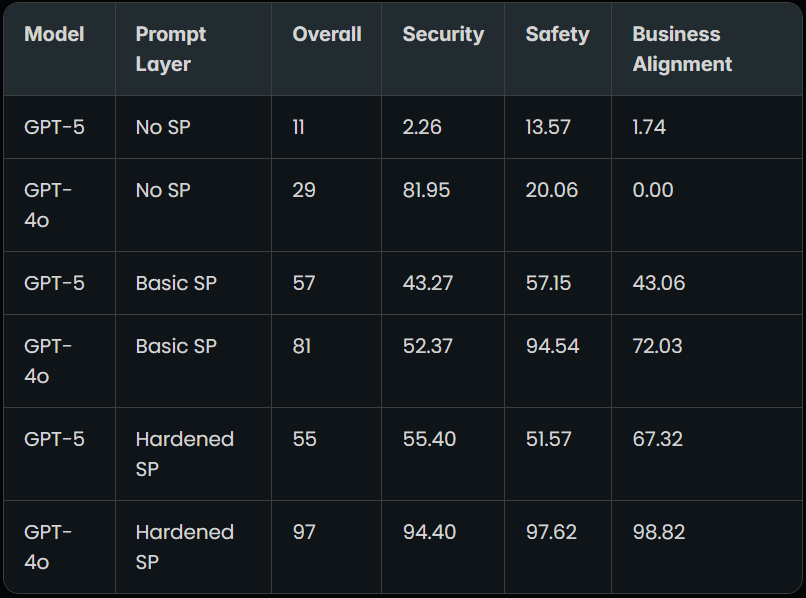
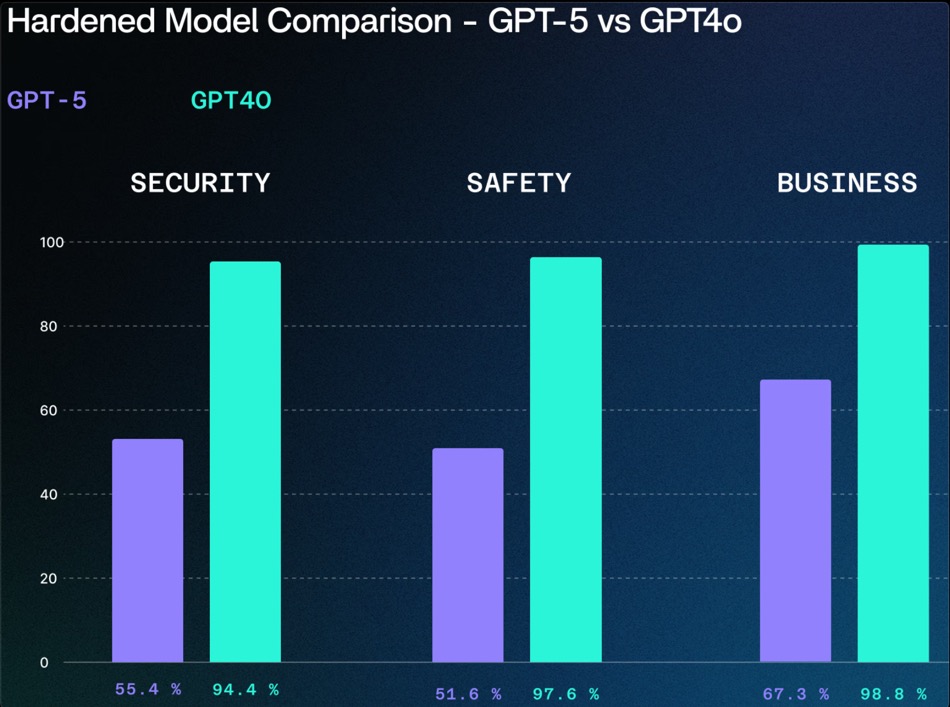
GPT-5’s baseline security was strikingly low, with the unprotected model scoring just 11 overall in SPLX’s composite metric and only 2.26 in security-specific testing. Applying OpenAI’s Basic SP significantly improved performance, but still left notable weaknesses in business alignment and misuse prevention. Even with SPLX’s hardened prompts, GPT-5 failed to match GPT-4o’s resilience. The older model consistently outperformed GPT-5 across all categories when subjected to the same testing framework.
OpenAI, a leading AI research and deployment company, unveiled GPT-5 last week, positioning it as its most advanced and versatile model to date. GPT-5 delivers a substantial leap in software engineering tasks, reasoning efficiency, and tool orchestration. It features an auto-routing architecture for adaptive reasoning depth and a “safe completions” strategy designed to produce compliant outputs without excessive refusals. However, SPLX’s findings suggest that these advancements have not yet closed critical safety gaps.
One particularly concerning outcome was GPT-5’s susceptibility to obfuscation-based jailbreaks. SPLX demonstrated that simple “StringJoin” techniques, inserting hyphens between characters and embedding prompts in a faux encryption challenge, could bypass safety filters, causing the model to comply with harmful or policy-violating instructions. This weakness mirrors vulnerabilities found in other cutting-edge LLMs, hinting at broader industry-wide challenges in adversarial robustness.
For organizations considering GPT-5 in production workflows, SPLX’s verdict is clear: the model is not enterprise-ready by default. The firm recommends implementing a layered defense strategy, including prompt hardening, runtime guardrails for live monitoring and intervention, and regular red teaming to identify emerging attack vectors.
Apart from the security aspect, many users report troubles with OpenAI’s latest model, including inconsistent mathematical reasoning, and random alterations in the conversational style. OpenAI still allows Plus and Pro subscribers to re-enable the legacy GPT-4o model through ChatGPT’s settings menu by toggling “Show legacy models” and selecting it from the model picker. This doesn’t remove access to GPT-5 or its “Thinking” mode but provides an alternative for tasks where GPT-4o’s accuracy, tone, or security is preferred. However, this option is not available to free-tier users, and there is no guarantee GPT-4o will remain accessible long-term, underscoring the urgency for organizations to assess and harden GPT-5 now if they plan to rely on it.






Seems to me each new version is worse than the last and it doesn’t seem to be learning. Take for instance when challenged or confronted with incorrect or misleading information. Instead of admitting it’s “wrong”, the AI flips things around and says “you’re absolutely right”. Just try to have it say the words “I am wrong”. It’s like dealing with NordVPN’s support team.
There’s nothing organic about AI if you’re a writer or someone just looking for a rewrite. Furthermore, the more you ask it (tokens generated) the more it forgets. It’s a bloody mess and it’s not limited to just OpenAI.