
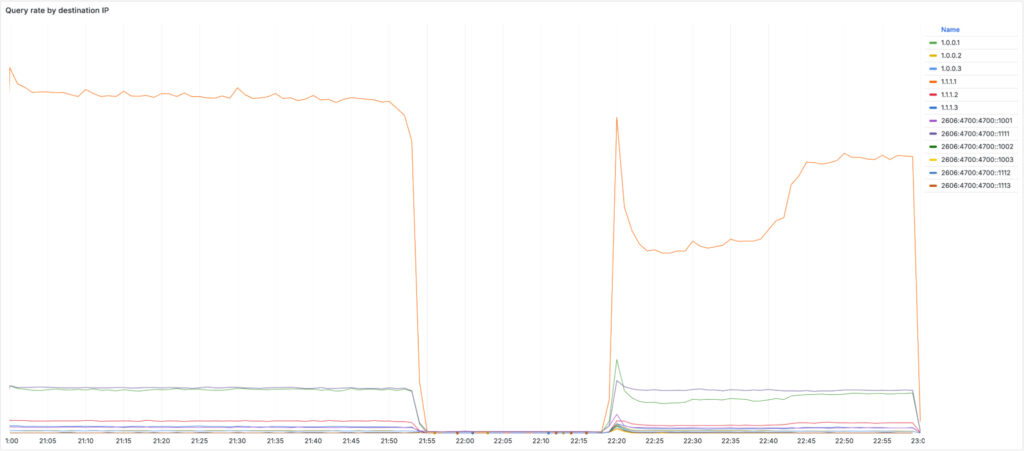
On July 14, 2025, Cloudflare's popular 1.1.1.1 DNS Resolver service became globally unavailable for over an hour, disrupting name resolution and effectively cutting off internet access for millions of users.
The outage, caused by a configuration error in Cloudflare's routing systems, began at 21:52 UTC and was fully resolved by 22:54 UTC.
The incident was documented in a postmortem published by Cloudflare engineers, according to which the root cause was traced to a configuration change made on June 6, 2025, during preparations for a future Data Localization Suite (DLS) service. A misconfigured service topology inadvertently included IP prefixes for the 1.1.1.1 resolver in a non-production DLS routing setup. Though the change initially had no effect, a later update on July 14 triggered a full global routing refresh, which caused these resolver prefixes to be withdrawn from production entirely.
Cloudflare
Cloudflare is a major internet infrastructure company that provides CDN services, DNS, DDoS protection, and a suite of security tools used by businesses, governments, and individual users worldwide. Its 1.1.1.1 DNS service, launched in 2018, is widely recognized for prioritizing speed and privacy, and is used as a default resolver by many ISPs, browsers, and privacy-conscious users.
The outage impacted multiple IP ranges associated with the resolver, including:
- IPv4: 1.1.1.0/24, 1.0.0.0/24, 162.159.36.0/24, 162.159.46.0/24, 172.64.36.0/24, 172.64.37.0/24, 172.64.100.0/24, 172.64.101.0/24
- IPv6: 2606:4700:4700::/48, 2606:54c1:13::/48, 2a06:98c1:54::/48
During the incident, traffic to these prefixes dropped sharply across UDP, TCP, and DNS-over-TLS (DoT). DNS-over-HTTPS (DoH) traffic remained largely unaffected, as most DoH clients access the resolver via the domain cloudflare-dns.com, which uses different IPs and routing logic.
Interestingly, the withdrawal of Cloudflare's routes unintentionally exposed a separate issue: a BGP origin hijack of 1.1.1.0/24 by Tata Communications (AS4755). Although unrelated to the outage, this hijack became visible only because Cloudflare's legitimate advertisements had been pulled. Cloudflare is following up with Tata Communications on the matter, but confirmed that this was not a contributing factor to the resolver failure.
The service was restored in two phases. At 22:20 UTC, Cloudflare began readvertising the affected prefixes after reverting the faulty configuration. However, due to automatic reconfiguration of edge servers during the outage, about 23% of them had dropped the necessary IP bindings. Full service recovery required accelerated reconfiguration, and by 22:54 UTC, DNS traffic had returned to normal levels globally.
Cloudflare acknowledged that the incident was exacerbated by reliance on legacy infrastructure for managing service topologies. The affected configuration was reviewed and approved by engineers but did not undergo progressive deployment or health monitoring, a limitation of the older system.
As a corrective measure, Cloudflare is now accelerating the deprecation of its legacy routing systems in favor of a modern architecture that supports staged rollouts and automated rollback mechanisms. This will reduce the risk of future global outages due to isolated configuration errors.
Users can increase resilience against unforeseen DNS outages by configuring multiple resolvers on their system/router, and using DNS-over-HTTPS (DoH) where possible, as it can route through different infrastructures.






Leave a Reply