
On November 14, 2024, Cloudflare experienced a critical incident that disrupted its log delivery service, impacting about 55% of the logs typically sent to customers over a 3.5-hour period. This data loss affected most Cloudflare Logs customers, prompting the company to release a detailed post-mortem and commit to preventing similar incidents.
Cloudflare Logs is an integral service for Cloudflare customers, generating detailed event metadata for purposes like compliance, observability, and analytics. The company handles around 50 trillion customer event logs daily, with Logpush delivering 4.5 trillion logs directly to customer destinations.
The system relies on a complex architecture involving several components:
- Logfwdr: Collects and batches logs for forwarding.
- Logreceiver: Further processes and sorts logs, handling approximately 45 PB of data daily.
- Buftee: Buffers logs to manage differing processing speeds, ensuring no “head of line” blocking between customers.
- Logpush: Delivers logs in structured batches to customer-defined destinations.
The November 14 incident highlighted vulnerabilities in this intricate pipeline, especially in fail-safe configurations and capacity planning.

Cloudflare
How it happened
The issue originated from a configuration update intended to support a new dataset for Cloudflare's Logpush service. A bug in the update caused a blank configuration to be sent to Logfwdr, the internal service responsible for forwarding event logs across Cloudflare's systems. This misconfiguration effectively stopped all customer logs from being processed.
The team reverted the change within five minutes, but the recovery attempt triggered a latent bug in Logfwdr's fail-safe mechanism. This fail-safe, designed to prevent data loss by “failing open” during configuration issues, inadvertently sent logs for all customers instead of just those with active Logpush jobs. This overwhelmed downstream systems.
One critical bottleneck emerged in Buftee, Cloudflare's buffering service. Buftee is designed to manage individual buffers for each customer's logs. The sudden spike in log traffic caused Buftee to attempt to create roughly 40 times the normal number of buffers, from an average of 1 million globally to over 40 million. This unexpected surge rendered Buftee unresponsive, requiring a full system reset and hours of recovery efforts.
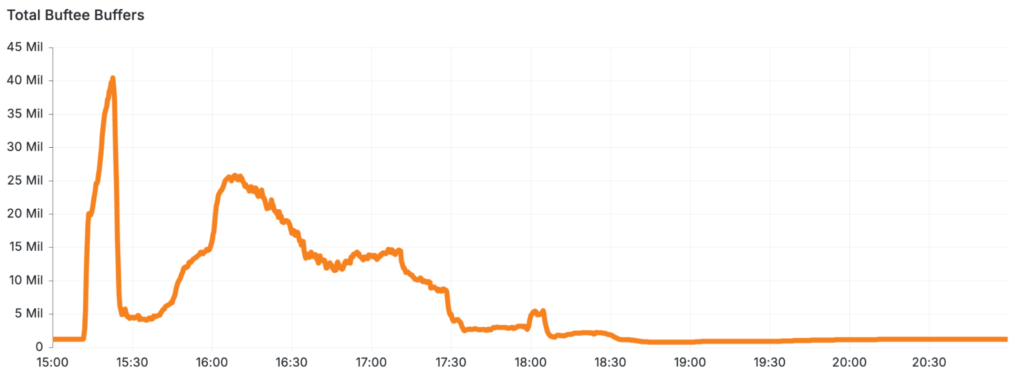
Additionally, the mechanisms built into Buftee to handle such overload scenarios were improperly configured, likened by Cloudflare to an unfastened seatbelt — present but ineffective when needed.
Preventing future incidents
Cloudflare has committed to several corrective measures:
- Improved monitoring with new alerts to detect misconfigurations like the blank Logfwdr configuration.
- Perform regular “overload tests” to simulate extreme conditions and identify weaknesses in production systems.
- Refine fail-safes and ensure all system components are prepared for unexpected stress.
Cloudflare customers are recommended to review internal log monitoring systems to ensure redundancy for critical data and consider using Cloudflare's Logpush filtering options to better control log delivery.






Leave a Reply