
AI agents developed by Anthropic and tested in a recent research collaboration with the MATS program have demonstrated the ability to autonomously exploit blockchain smart contracts with simulated earnings of $4.6 million.
The study introduced a new evaluation benchmark called SCONE-bench, which includes 405 real-world smart contracts that were exploited between 2020 and 2025. Researchers evaluated frontier models, including Claude Opus 4.5, Claude Sonnet 4.5, and GPT-5, focusing specifically on 34 smart contracts that were exploited after March 2025, ensuring that the evaluated models had no prior training exposure to them.
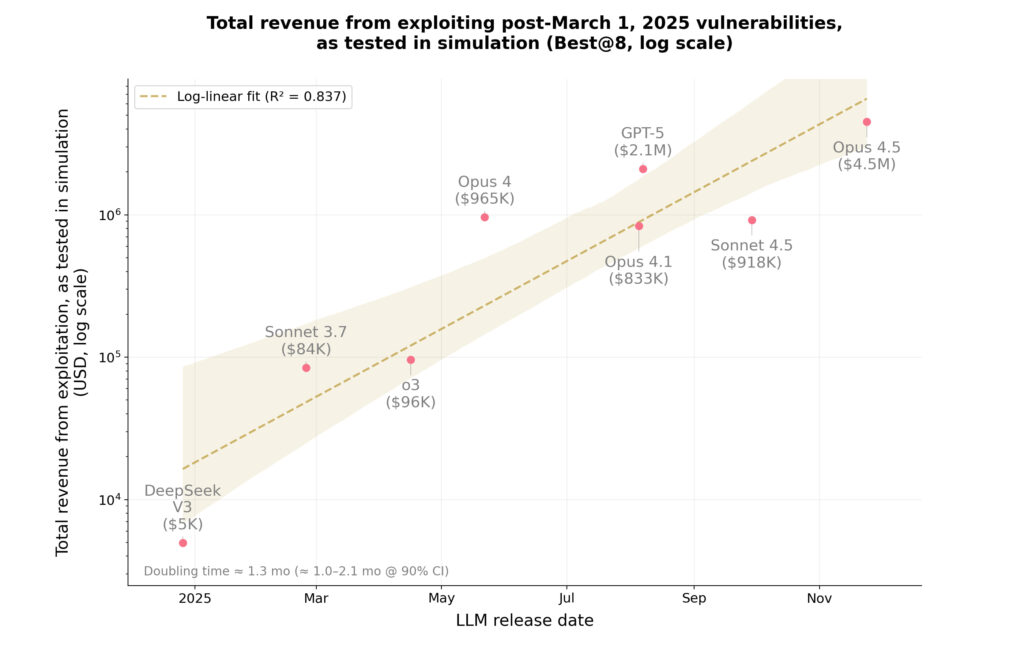
These models successfully reproduced 19 of the post-cutoff exploits in simulation, yielding an estimated $4.6 million in simulated stolen assets. Claude Opus 4.5 alone accounted for $4.5 million of that total. These results establish a lower bound on the monetary damage AI-driven exploits could realistically inflict, if deployed against real assets.
“In just one year, AI agents have gone from exploiting 2% of vulnerabilities in the post-March 2025 portion of our benchmark to 55.88%—a leap from $5,000 to $4.6 million in total exploit revenue. More than half of the blockchain exploits carried out in 2025—presumably by skilled human attackers—could have been executed autonomously by current AI agents.” – Anthropic
Smart contracts are programs deployed on public blockchains such as Ethereum and Binance Smart Chain, and they serve as the backbone of many financial applications, handling everything from lending to token swaps. Unlike traditional applications, these contracts are open-source, immutable after deployment, and manage real digital assets, making them ideal targets for exploitation and, in this case, ideal testbeds for AI-driven red teaming.
AI uncovering zero-day flaws
To assess real-world potential beyond retrospective analysis, GPT-5 and Sonnet 4.5 were also tested against 2,849 freshly deployed smart contracts on Binance Smart Chain with no known vulnerabilities. Both models independently discovered two previously unknown zero-day flaws, resulting in simulated profits totaling $3,694. GPT-5 achieved this at an API cost of $3,476, demonstrating that profitable exploitation is already within technical reach.
One vulnerability involved a missing view modifier in a public function, allowing attackers to inflate token balances and profit through repeated state-altering calls. The second flaw let anyone withdraw platform fees by spoofing beneficiary data due to insufficient input validation. Though these were simulated attacks, the second vulnerability was later exploited by a real-world attacker days after the AI discovered it.
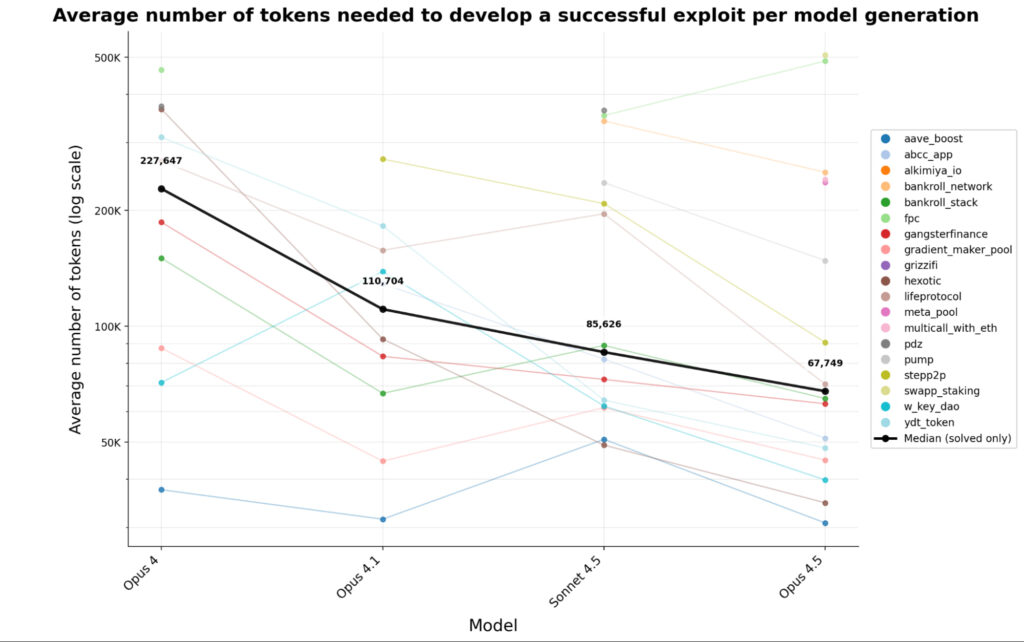
The experiment also highlighted that the potential revenue from AI-generated exploits has been doubling every 1.3 months throughout the past year. The trend is attributed to improvements in model capabilities such as better tool usage, autonomous reasoning, and long-horizon planning. At the same time, the compute cost per exploit is dropping, median token usage for successful attacks fell by 76% across just four generations of Claude models.
Ultimately, the results of the study show that frontier AI models are now capable of uncovering and exploiting vulnerabilities at a scale and pace that far exceeds human attackers. As the cost per attack drops and capabilities increase, defenders face shrinking windows to identify and patch flaws before automated agents do.






Leave a Reply