
Google has unveiled a new security framework for agentic capabilities in Chrome, laying the foundation for Gemini-powered web agents that can perform tasks across sites on behalf of users.
The new architecture, announced by Chrome engineer Nathan Parker, introduces layered defenses to counter prompt injection attacks and ensure agent actions remain aligned with user intent.
Agentic browsing, where an AI agent automates complex user tasks such as filling out forms or navigating multiple websites, offers powerful functionality but also introduces new security risks. The most pressing of these is indirect prompt injection, where untrusted web content manipulates the AI into acting maliciously. To address this, Google is introducing several key security innovations.
At the core of the new system is the User Alignment Critic, a secondary Gemini-based model that verifies whether each proposed agent action aligns with the user’s goal. This model operates in isolation from untrusted web content, reducing the risk of being manipulated by malicious input. If an action is deemed unsafe or misaligned, it is vetoed before execution, and the agent must replan or return control to the user.
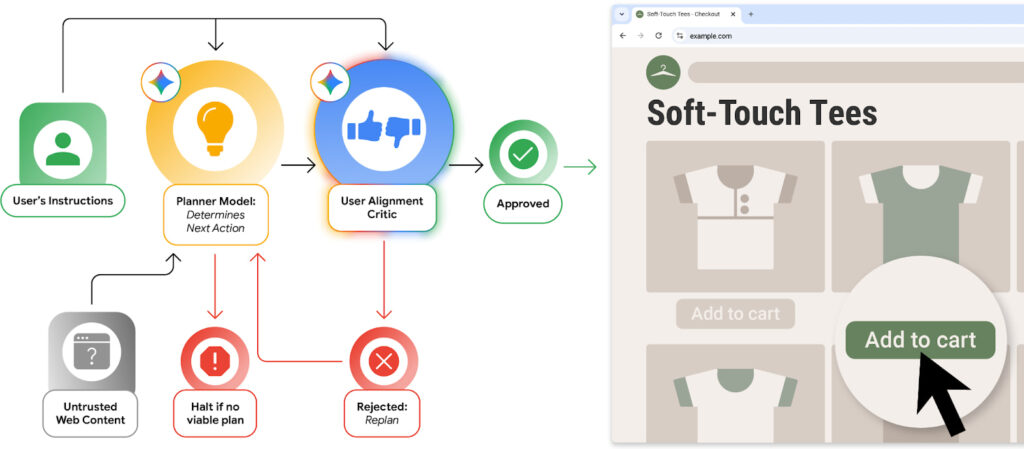
To contain where and how agents can operate, Google is also implementing Agent Origin Sets, an extension of Chrome’s origin isolation model. Each task session defines a list of read-only and read-write web origins the agent can access. This ensures the agent only interacts with domains relevant to the task and blocks cross-site data exfiltration. New origins must pass through a gating system before inclusion, and even model-generated URLs are checked against a whitelist to prevent abuse.
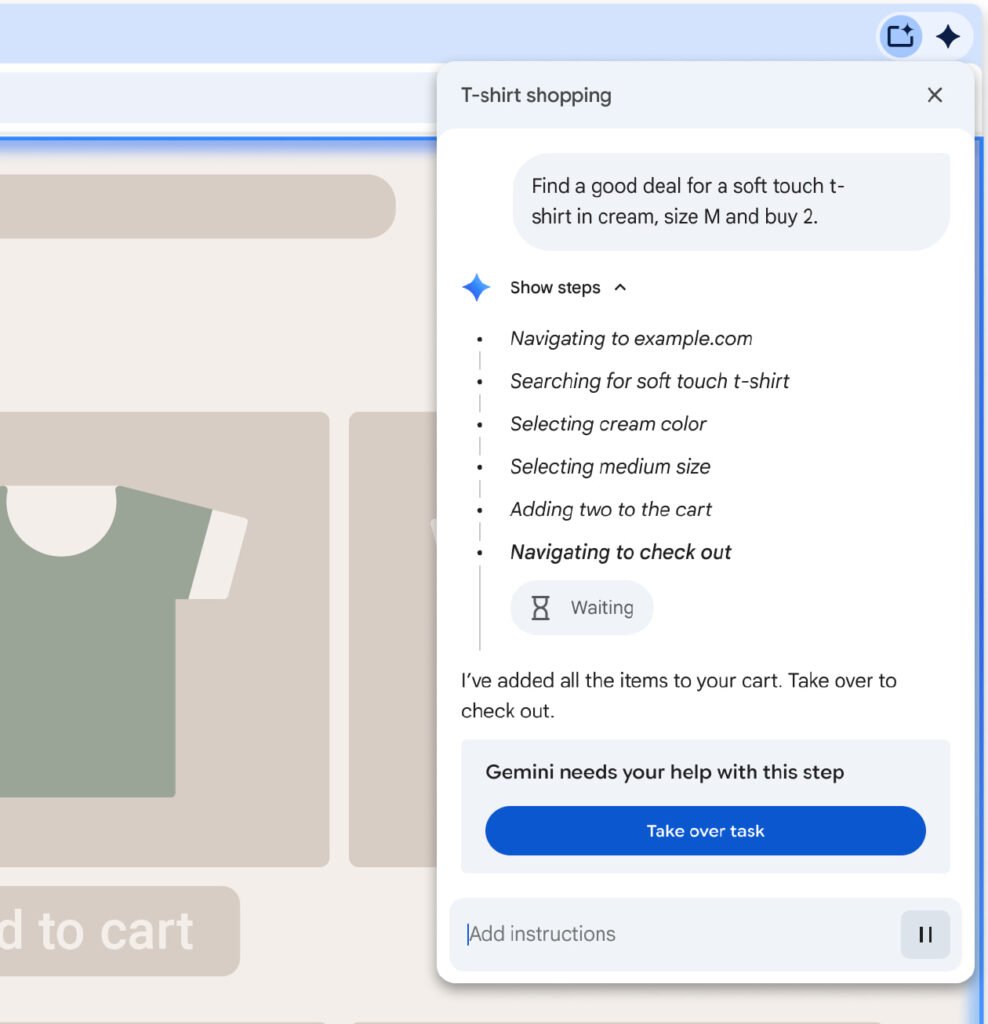
Chrome, with over 3 billion users, has long championed browser security, and this latest update extends that commitment into the AI era. Gemini agents in Chrome will now operate under strict user oversight, with actions logged in real time and key steps, like logging into accounts, accessing financial sites, or completing purchases, requiring explicit user confirmation.
To detect malicious manipulation, a prompt-injection classifier runs in parallel with the agent, flagging any attempts to socially engineer the model. This works alongside existing protections like Safe Browsing and on-device AI that target phishing and scams.
Google is also using automated red-teaming systems to simulate attacks on its AI agents, leveraging synthetic malicious sites and LLM-generated attacks. These tests focus on high-risk vectors like user-generated content and aim to preempt real-world exploits.
In a nod to the security research community, Google has updated its Vulnerability Rewards Program, offering up to $20,000 for discoveries that breach the new agentic security boundaries.






“To detect malicious manipulation”
google IS the malicious manipulator